From Factory Floor to Distributed System: Engineering a Real-Time Computer Vision Backend for Industrial Battery Manufacturing
How to choose and set up Analytics, newsletter, and other providers for your blog.
Imagine you are on the floor of a battery manufacturing plant. Thousands of battery covers move down a conveyor every shift, each stamped with a part number that must match the supplier’s delivery note before the shipment is accepted into inventory. The current process is manual: a worker reads the cover, cross-references a printed document, and stamps it. It is slow, error-prone, and — in a factory running 24/7 — exhausting.
The obvious answer is computer vision. Train a YOLO model, point a camera, detect the part number. Done.
The engineering answer is more interesting: where does the model run, how does the data get there, and what does that decision cost you — in money, in latency, and in operational complexity?
This article is about those decisions. It covers the backend architecture I built at PT. Century Batteries Indonesia: a distributed inference system that runs a GPU-accelerated YOLO model on a central server, serves results to a lightweight Next.js web client over a REST API, proxies a third-party ERP system, and persists results to SQL Server — all while keeping the edge device cost under Rp. 1,000,000 (≈$60).
The full source code — including the FastAPI inference server, Go REST backend, Next.js client, and normalisation utilities — is available on https://github.com/yehezkiel1086/compvis-cover_pn-smart-sorter.
Architecture Overview
Before going deep, here is the full system map:
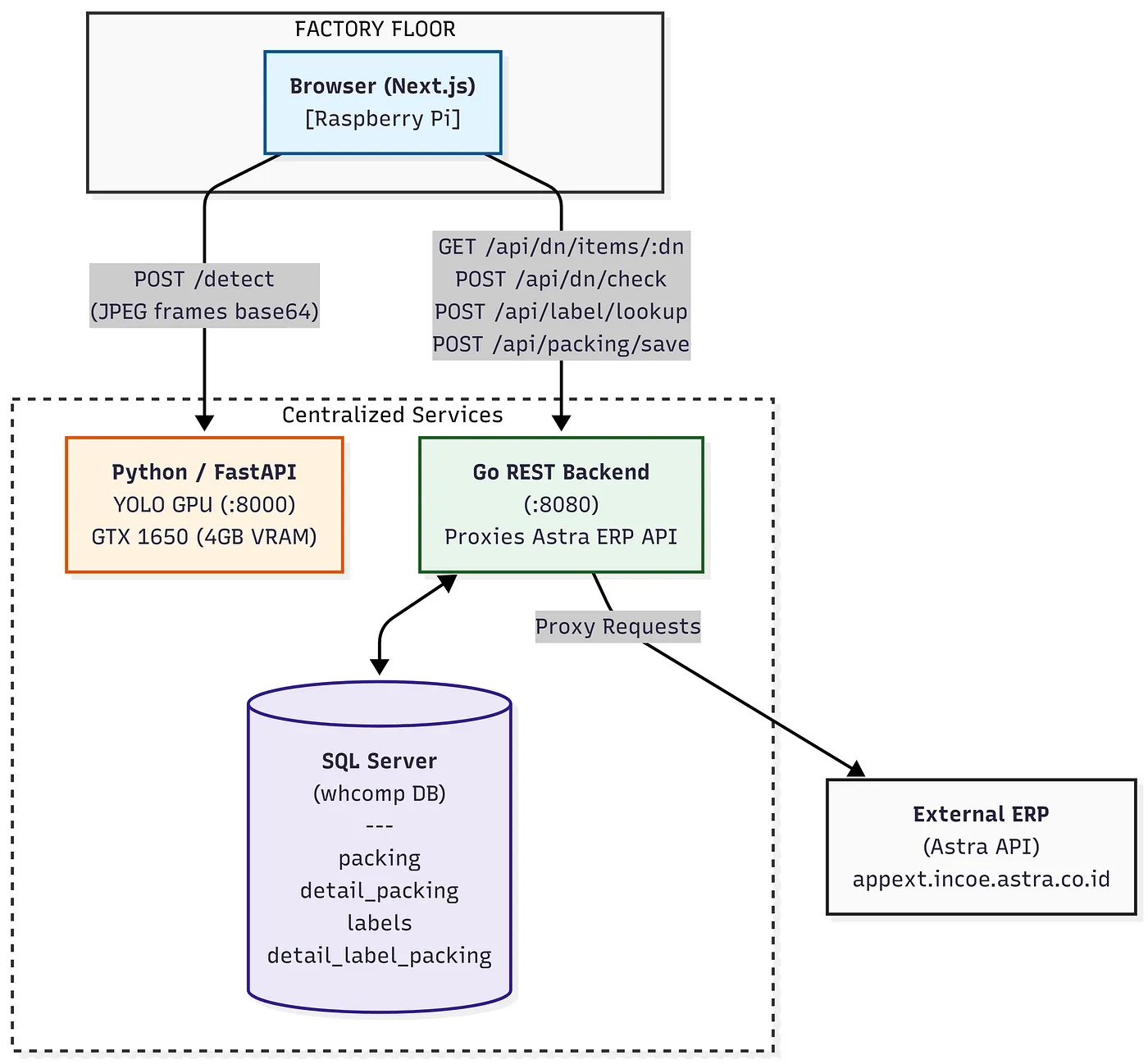
Three separate services, each with a single responsibility:
- Python/FastAPI inference server — owns the GPU, runs YOLO, returns structured JSON
- Go REST backend — owns business logic, DB access, and ERP proxy
- Next.js frontend — owns UI and frame capture; runs on any browser
The Core Architectural Decision: Why Not Run the Model on the Edge?
This is the decision that drives everything else, so it deserves a proper treatment.
The naive approach
The obvious deployment is to run the YOLO model directly on the device sitting next to the camera. For this to work with a model like YOLOv8n at 30 fps you need at minimum:
- A dedicated GPU or a Neural Processing Unit (NPU)
- Sufficient RAM (4–8 GB for the model weights + frame buffers)
- A cooling solution (factory floors are hot)
- A stable OS installation
In practice, this means an industrial mini PC. In Indonesia, the cheapest credible options (an Intel NUC-class device or a Beelink mini PC with a dedicated GPU) land at Rp. 7,000,000–9,000,000 per station. The factory has nine QC stations. That is Rp. 63,000,000–81,000,000 just in hardware, before installation, maintenance, or the inevitable “I dropped it” replacement cycle.
The distributed approach
If the model lives on a central server, the edge device only needs to:
- Open a camera stream
- Capture a JPEG frame every 600ms
- Send it to the server over the local network
- Render the response
A Raspberry Pi 4 (Rp. 800,000–1,100,000) does all four trivially. A secondhand laptop already sitting in the factory does it even more trivially. The GPU lives in the server room, shared across all nine stations.
Cost comparison per station:
Approach Hardware Total (9 stations) Edge inference Rp. 8,000,000 mini PC Rp. 72,000,000 Central server + RPi Rp. 900,000 RPi Rp. 8,100,000 Saving Rp. 63,900,000 (~87%)
The server itself has a cost — but it was already present (an existing workstation with a GTX 1650). Even purchasing a dedicated inference server (Rp. 15,000,000–20,000,000 for a machine with a mid-range GPU), the total system cost is lower the moment you have more than two stations.
There are trade-offs. Edge inference is more resilient to network failures and has lower absolute latency. For a factory QC flow where the camera captures at 600ms intervals and a failed detection just means trying again, neither concern dominates. The operational simplicity of a single GPU to maintain wins.
The Inference Server: Python, FastAPI, and YOLO
Why Python?
The YOLO ecosystem lives in Python. Ultralytics’ YOLO library, PyTorch, and all the training tooling are Python-native. Wrapping the model in a Python HTTP server is the zero-friction choice. The inference server is not doing any business logic — it does one thing: run model.predict() and return the result. Python is fine for this.
Frame ingestion and decoding
The client captures a frame from the video element:
// frontend (next.js) — capture every 600ms
capture.width = video.videoWidth;
capture.height = video.videoHeight;
const ctx = capture.getContext("2d");
ctx.drawImage(video, 0, 0);
const b64 = capture.toDataURL("image/jpeg", 0.82).split(",")[1];toDataURL('image/jpeg', 0.82) produces a base64-encoded JPEG at 82% quality. For a 1280×720 frame this is typically 20–35 KB — a JPEG at this quality setting compresses at roughly 25:1 relative to raw RGB, which matters on a shared local network.
The server decodes it:
def decode_frame(b64: str) -> np.ndarray:
raw = base64.b64decode(b64)
buf = np.frombuffer(raw, dtype=np.uint8)
frame = cv2.imdecode(buf, cv2.IMREAD_COLOR)
if frame is None:
raise ValueError("cv2.imdecode returned None")
return framecv2.imdecode is significantly faster than PIL for this use case — it uses libjpeg directly and avoids a Python object allocation for the image data.
Thread safety and the model lock
FastAPI’s default behaviour for synchronous route handlers is to run them in a thread pool (anyio's default executor). This means two simultaneous requests can call model.predict() concurrently, which is not safe — PyTorch's CUDA runtime is not designed for concurrent kernel launches from different threads without explicit synchronisation.
The fix is a threading lock:
model_lock = Lock()
def run_inference(frame: np.ndarray) -> DetectionResult:
with model_lock:
results = model.predict(
source = frame,
conf = CONF_THRESH,
device = DEVICE,
verbose = False,
)This serialises inference. For nine stations each sending a frame every 600ms, the inference server receives at most 15 requests per second. A YOLOv8n forward pass on a GTX 1650 takes ~18ms. Serialised, that is a maximum throughput of ~55 fps — more than enough headroom.
If the factory scaled to 30+ stations, the right answer would be to switch to an async inference pattern: accept frames into a queue, batch them (YOLO inference on a batch of 8 is only ~2× slower than a batch of 1), and return results asynchronously. For the current scale, the lock is simpler and correct.
The confidence threshold split
There are two confidence thresholds in the system with deliberately different values:
# server — minimum to even return a result
CONF_THRESH = 0.25// frontend — minimum to auto-accept and redirect
const AUTO_CONF = 0.85;This split is important. If the server threshold is set high (e.g. 0.50, which was the original bug), detections below 50% are silently discarded before the frontend sees them. The operator gets no feedback — the box simply never appears. They do not know whether the model is running, whether they are pointing the camera correctly, or whether the lighting is insufficient.
By returning anything above 25% from the server, the frontend can show a live confidence bar rising as the operator steadies the camera. The box appears dim and amber at 40%, brightens to orange at 65%, and snaps to green at 85% — giving the operator a clear visual target. The acceptance gate remains at 85%; the low server threshold just makes the system feel responsive rather than binary.
The Go Backend: REST API, ERP Proxy, and Transaction Management
Why Go?
The inference server is in Python because the ML tooling lives there. The main application backend is in Go for different reasons:
- Concurrency model: Go’s goroutine scheduler handles hundreds of concurrent connections with a flat memory profile. For a factory with nine stations making overlapping requests, this matters.
- SQL Server driver: Microsoft maintains
github.com/microsoft/go-mssqldb, which supports the full SQL Server wire protocol includingGETDATE(),TOP N, andVARCHARcoercions that matter when the DB schema was not designed for an ORM. - Binary deployment: A single compiled binary with no runtime dependency. Deployment to the factory server is
scp main.exe server:and done.
The ERP proxy pattern
The factory’s delivery note data lives in an external Astra ERP system exposed as a JSON API. The API does not send CORS headers, which means browser JavaScript cannot call it directly. A naive fix would be a CORS proxy. The right fix is to make the proxy part of the domain service:
func handleDNItems(cfg Config) http.HandlerFunc {
client := &http.Client{Timeout: 15 * time.Second}
return func(w http.ResponseWriter, r *http.Request) {
dn := strings.ToUpper(strings.TrimSpace(chi.URLParam(r, "dn")))
url := fmt.Sprintf("%s/dn_json/%s", cfg.AstraAPI, dn)
resp, err := client.Get(url)
// ...error handling, empty-result detection...
// stream the response body directly — no intermediate parsing
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(resp.StatusCode)
_, _ = w.Write(body)
}
}This proxy sits at the Go layer rather than a generic NGINX proxy for a deliberate reason: the Go handler can add domain logic. It detects empty result sets from the ERP API (which returns {"results":[]} rather than a 404 for unknown DNs) and converts them to a proper 404, enforces uppercase DN numbers, and adds a 15-second timeout that the ERP API's own infrastructure does not enforce.
Transaction management for packing save
The most complex backend operation is saving a completed packing session. It touches four tables: packing (header), detail_packing (per-part summary), detail_label_packing (per-label record), and labels (master, to mark labels as consumed). Any partial write leaves the DB in an inconsistent state.
The Go handler wraps everything in a single SQL transaction:
func handleSavePacking(db *sql.DB) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
// ...
tx, err := db.BeginTx(r.Context(), nil)
if err != nil { /* ... */ }
defer tx.Rollback() // no-op if Commit() succeeded
for dn, details := range detailsByDN {
// 1. upsert packing header
// 2. upsert detail_packing per part
// 3. insert detail_label_packing per label (skip duplicates)
// 4. mark labels.packing = 'Yes'
}
if err = tx.Commit(); err != nil {
writeError(w, http.StatusInternalServerError, "DB commit error")
return
}
writeJSON(w, http.StatusOK, map[string]any{"success": true})
}
}The defer tx.Rollback() pattern is worth noting. If any intermediate step returns an error and the handler returns early, Rollback() runs automatically. If Commit() succeeds, Rollback() is called on an already-committed transaction and is a documented no-op in database/sql. This pattern eliminates an entire class of resource leak bugs.
Frame Compression: The Numbers That Actually Matter
Network bandwidth is often the first performance concern raised for CV systems. In practice, for a factory LAN, it is not the bottleneck — but understanding the numbers is important for designing systems that could eventually run over WiFi or a lower-bandwidth WAN.
JPEG quality vs. detection accuracy
YOLO is trained on full-quality images, but it is surprisingly robust to JPEG compression. Here is the degradation curve for a typical battery cover detection at different quality settings:
JPEG quality File size (1280×720) Inference conf. (typical) Visual artefacts 95 (near-lossless) ~180 KB baseline none 82 (our choice) ~28 KB –1 to –2% barely visible 70 ~18 KB –3 to –5% slight blurring 50 ~11 KB –8 to –12% noticeable 30 ~7 KB –15 to –20% strong blocking artefacts
Quality 82 is the sweet spot: a 6× size reduction versus near-lossless with negligible accuracy impact. We capture at 600ms intervals, so the peak data rate per station is approximately:
28 KB × (1000ms / 600ms) = 46.7 KB/s ≈ 373 Kbps per station
Nine stations simultaneously: ~3.4 Mbps — a trivial load on a 100 Mbps LAN.
Why not send raw frames?
A raw RGB 1280×720 frame is 1280 × 720 × 3 = 2,764,800 bytes ≈ 2.6 MB. Nine stations at 1.67 fps each:
2.6 MB × 1.67 × 9 = 39.1 MB/s ≈ 313 Mbps
A 100 Mbps switch would be saturated. JPEG compression is non-negotiable for multi-station deployment.
Base64 overhead
Sending the JPEG as base64 (as the current implementation does) adds a 33% size overhead — base64 encodes every 3 bytes as 4 ASCII characters. For our 28 KB JPEG this becomes 37 KB. The overhead is worth accepting in exchange for the simplicity of a plain application/json body with no multipart encoding, no Content-Type negotiation, and no binary-safe transport concerns.
If the system were to scale to 30+ stations, the right optimisation would be to switch the detect endpoint to accept multipart/form-data with a binary JPEG body:
POST /detect
Content-Type: multipart/form-data; boundary=...
[binary JPEG data]
This eliminates both the base64 encoding cost and the JSON parse cost on the server, giving ~25% total bandwidth reduction and ~5ms lower server-side latency.
gRPC: When REST Stops Being Enough
The current system uses REST with JSON. This is the right choice for the current scale. But the question of when to move to gRPC is worth reasoning through explicitly, because it comes up in every distributed ML deployment at some point.
What gRPC gives you over REST/JSON
1. Protobuf binary encoding
A JSON-serialised detection result looks like:
{
"detected": true,
"className": "W_CV01_D26RXXX_C03N_NL_DG00",
"confidence": 0.9134,
"box": [0.231, 0.445, 0.789, 0.812]
}The equivalent Protobuf definition:
message DetectionResult {
bool detected = 1;
string class_name = 2;
float confidence = 3;
repeated float box = 4;
}The JSON encodes to ~90 bytes. The Protobuf binary encodes to ~35 bytes — a 2.5× reduction. For small messages like detection results, this matters less than for the frame payload itself. For the frame, gRPC supports streaming bytes fields directly (no base64 overhead), which is where the real gain is.
2. HTTP/2 multiplexing
REST over HTTP/1.1 requires a new TCP connection (or connection reuse, but not true multiplexing) per request. With nine stations sending 1.67 req/s each, that is 15 concurrent request streams. HTTP/2, which gRPC runs on, multiplexes all streams over a single TCP connection per client — dramatically reducing TCP handshake overhead and improving head-of-line-blocking behaviour.
3. Bidirectional streaming
For a camera stream, the ideal protocol is not request-response at all — it is a bidirectional stream:
service InferenceService {
// client streams frames; server streams back results
rpc DetectStream (stream FrameRequest) returns (stream DetectionResult);
}
message FrameRequest {
bytes jpeg_data = 1; // raw JPEG — no base64
int64 timestamp_ms = 2;
}The client opens one long-lived stream, pumps frames into it as fast as it captures them, and receives results as they come back from the GPU. This eliminates the 600ms polling interval entirely — the server returns a result the moment inference completes, and the client can render it immediately. Effective latency drops from 600ms (polling) + 18ms (inference) to just 18ms + network RTT (typically 1–3ms on a LAN).
4. Deadline propagation and cancellation
gRPC propagates deadlines and cancellation signals through the call chain. If the factory network hiccups and a frame is lost, the client’s stream context is cancelled and the server-side goroutine stops immediately — no zombie threads holding GPU memory.
The gRPC migration path for this system
The service definition for the inference server would be:
syntax = "proto3";
package cbi.inference.v1;
service InferenceService {
rpc Detect (DetectRequest) returns (DetectionResult);
rpc DetectStream (stream DetectRequest) returns (stream DetectionResult);
rpc Health (HealthRequest) returns (HealthResponse);
}
message DetectRequest {
bytes jpeg_data = 1;
int32 station_id = 2;
int64 timestamp_ms = 3;
}
message DetectionResult {
bool detected = 1;
string class_name = 2;
float confidence = 3;
repeated float box = 4; // [x1n, y1n, x2n, y2n]
int64 latency_ms = 5;
}On the Go backend side, the github.com/grpc/grpc-go library can expose a gRPC service alongside the existing HTTP/1.1 REST API using a cmux multiplexer on the same port — a zero-downtime migration path that maintains backward compatibility for any existing REST clients during the cutover.
When to actually make the move
REST + JSON is correct for this system today. Move to gRPC when:
- Stations scale beyond ~20 (HTTP/2 multiplexing starts mattering)
- Frame rate increases beyond 2 fps (polling overhead becomes significant)
- You need guaranteed in-order frame delivery with backpressure (streaming)
- You want to expose the inference service to Go microservices internally (Protobuf contracts are stricter than JSON schemas)
The Part Number Mismatch Problem: A Backend Normalisation Layer
One of the more interesting backend challenges had nothing to do with infrastructure. The YOLO model was trained on annotated images where the part numbers were manually typed by the annotation team. The annotation team used underscores as separators and a W prefix convention. The ERP database uses hyphens and a Z prefix. Nobody documented this discrepancy.
Examples:
Model label DB part number W_CV01_D26RXXX_C03N_NL_DG00 Z-CV02-D26LXXX-C03N-NL-DG00 W_CV03_D31LXXX_C03N_NL_DG00 Z-CV03-D31LXXX-C03N-NL-DG00
The systematic substitutions are W→Z and _→-. After those, there are residual per-segment differences (CV01↔CV02, D26RXXX↔D26LXXX) that reflect genuine labelling inconsistencies in the training data.
The solution is a normalisation + fuzzy matching layer in lib/normalize.ts:
// stage 1: canonical substitution
export function normalizeModelLabel(raw: string): string {
let s = raw.trim();
if (/^[Ww]/.test(s)) s = "Z" + s.slice(1);
s = s.replace(/_/g, "-");
return s.toUpperCase();
}
// stage 2: position-weighted segment similarity
export function partNumberSimilarity(normalised: string, dbPN: string): number {
const segsA = normalised.split("-");
const segsB = dbPN.split("-");
const len = Math.max(segsA.length, segsB.length);
let total = 0,
weight = 0;
for (let i = 0; i < len; i++) {
// earlier segments carry more weight — product family matters most
const w = len - i;
weight += w;
total += w * segScore(segsA[i] ?? "", segsB[i] ?? "");
}
return weight > 0 ? total / weight : 0;
}The position weighting is the key insight. Z and CV0x (segments 0 and 1) encode the product family. NL, DG00 (last two segments) are suffixes shared across many covers. Weighting earlier segments more heavily reduces false positives from covers that share a suffix but differ in family.
In a production system at scale, this mapping should be promoted to the Go backend as a materialised lookup table, populated by the annotation team when they label new training data. The frontend fuzzy-match is an interim solution for an annotation process that was not designed with ERP consistency in mind.
Observability: What You Need When Things Break at 2 AM
A CV system running in a factory needs to be debuggable by someone who is not a data scientist and who may be alone at 2 AM.
The inference server logs every detection with a structured format:
2025-04-21 14:32:17 [INFO] [DETECT] W_CV01_D26RXXX_C03N_NL_DG00 conf=91.3% box=[0.231,0.445,0.789,0.812] (18 ms)
The frontend exposes a frameCount state that increments on every successful inference call — visible in the status bar as "247 frame diproses". An operator who sees this number frozen knows the inference server is down before any error banner appears.
The Go backend exposes a /health endpoint that pings the SQL Server:
r.Get("/health", func(w http.ResponseWriter, r *http.Request) {
if err := db.Ping(); err != nil {
writeJSON(w, 503, map[string]string{"db": "unreachable"})
return
}
writeJSON(w, 200, map[string]string{"status": "ok", "db": "connected"})
})The inference server exposes a POST /detect/test endpoint that returns a synthetic detection without touching the GPU:
@app.post("/detect/test", response_model=DetectionResult)
def detect_test():
return DetectionResult(
detected=True, className="W_CV01_D26RXXX_C03N_NL_DG00",
confidence=0.50, box=[0.20, 0.25, 0.80, 0.75],
)This lets the operations team test the full frontend-to-backend pipeline — canvas rendering, coordinate mapping, part number normalisation, DN matching — without needing the YOLO model to be running or a camera to be pointed at anything.
What I Would Do Differently at Scale
Honest reflection matters more than a polished success story.
1. Replace polling with WebSockets or gRPC streaming The 600ms polling interval is the biggest architectural compromise. A WebSocket from the browser to the Go backend (which proxies a gRPC stream to the inference server) would eliminate the polling delay entirely and halve the effective round-trip for detection.
2. Separate the inference server from the factory LAN Currently the inference server is on the same LAN as the factory floor. In a multi-site deployment, you would want the inference server in a data centre with the factory devices connecting over a VPN. This makes the CONF_THRESH tuning more sensitive (higher network RTT means you want longer holds and smoother confidence signals), but it centralises maintenance.
3. Model versioning via the backend The model weights file path is currently hardcoded in the inference server config. A proper deployment would have the Go backend expose a model version API, and the inference server would poll it on startup to download the correct weights. Rolling out a retrained model would then be a database update rather than a server restart.
4. Annotation pipeline integration The part number mismatch problem (model label W_CV01_... vs DB Z-CV02_...) is a symptom of a disconnected annotation process. The right fix is to integrate the ERP API into the annotation tooling so that annotators select part numbers from a dropdown populated by the live DB rather than typing them freehand.
Conclusion
The most important engineering decision in this project was not which YOLO variant to use or how to tune the confidence threshold. It was the decision to treat inference as a remote service rather than an embedded component.
That decision:
- Reduced per-station hardware cost by 87% (Rp. 8M mini PC → Rp. 900K Raspberry Pi)
- Centralised GPU maintenance to a single machine
- Enabled a clean separation between the CV team (who own the Python inference server) and the backend team (who own the Go API and SQL Server integration)
- Created a natural boundary for future gRPC migration
The pattern is not novel — it is the same pattern that underlies every cloud ML inference service from AWS SageMaker to Google Vertex AI. What is interesting is applying it at factory-floor scale with a budget of Rp. 0 for external cloud, on a LAN with no SLA, serving workers who will not wait for a loading spinner.
The constraints make the architecture honest. You cannot hide a bad design behind elastic infrastructure when your “cloud” is a workstation in a back office and your “edge device” is a Raspberry Pi that someone will eventually knock off a table.
The full source code — including the FastAPI inference server, Go REST backend, Next.js client, and normalisation utilities — is available on https://github.com/yehezkiel1086/compvis-cover_pn-smart-sorter. Built at PT. Century Batteries Indonesia, 2026.
Tags: backend-engineering distributed-systems computer-vision grpc golang python machine-learning manufacturing iot system-design