Building an Enterprise LMS for 600+ Users: Go Backend Engineering Deep Dive
How I designed and built the backend of PT. CBI's internal Learning Management System using Golang, hexagonal architecture, Redis, RabbitMQ, and a dual-database SQL Server setup — serving the entire company's workforce.
When PT. Century Batteries Indonesia (CBI) needed a centralized platform to manage employee upskilling, training compliance, and HR workforce analytics, I took on the challenge of building it from scratch. The result is a full-stack internal LMS actively used by 600+ employees — the company's entire workforce — running in production every working day.
The system is split into two major domains:
- Personal Development — where individual employees enroll in training modules (video, PDF, PowerPoint), take quizzes, and track their own skill progression against a competency matrix.
- Team Development — where managers and HR staff analyze workforce capabilities through dashboards, manage training modules, run TNA (Training Needs Analysis) workflows, and perform skill gap analysis against the Kamus Kompetensi Gol 1-3 (a 243-competency, 112-role matrix sourced from the company's 2022 competency catalogue).
This article focuses on the Go backend — the architecture decisions, system design patterns, and the engineering problems worth talking about.
Tech Stack
| Layer | Choice |
|---|---|
| Language | Go 1.22 |
| Web Framework | Gin |
| ORM | GORM |
| Primary Database | SQL Server (Azure-hosted, dual-DB) |
| Cache / Rate Limiter | Redis |
| Message Broker | RabbitMQ |
| Auth | JWT (access + refresh token, HttpOnly cookies) |
| File Storage | Cloudinary (quiz images), local disk (module thumbnails) |
| Frontend | Next.js 15 (App Router) |
| Architecture | Hexagonal (Ports & Adapters) |
System Architecture & ERD
Here’s the system architecture for the LMS’s Personal Development:
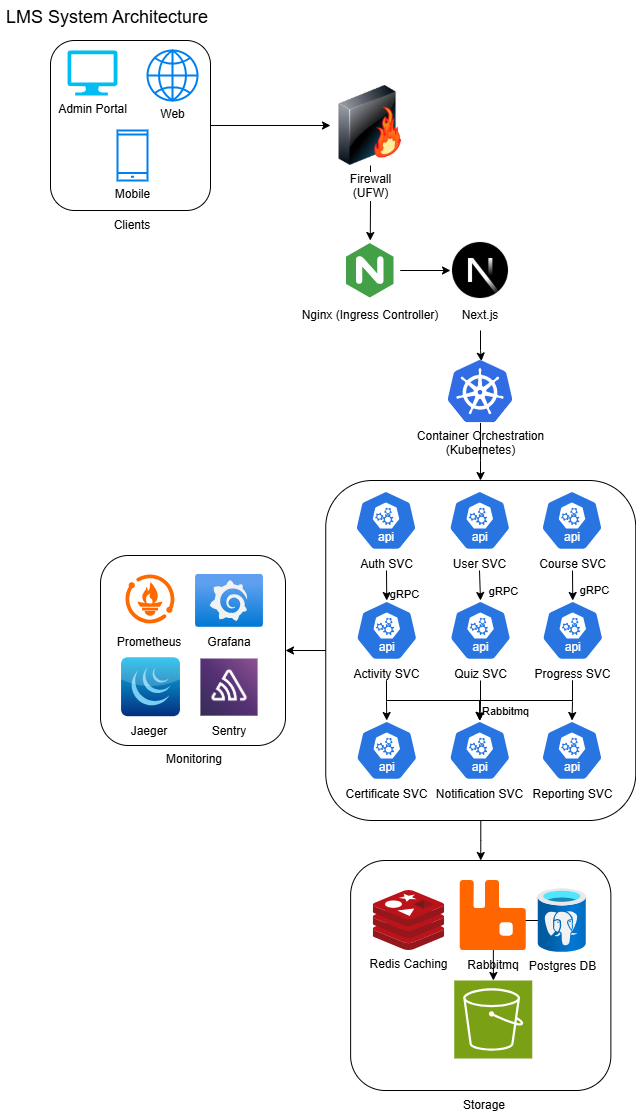
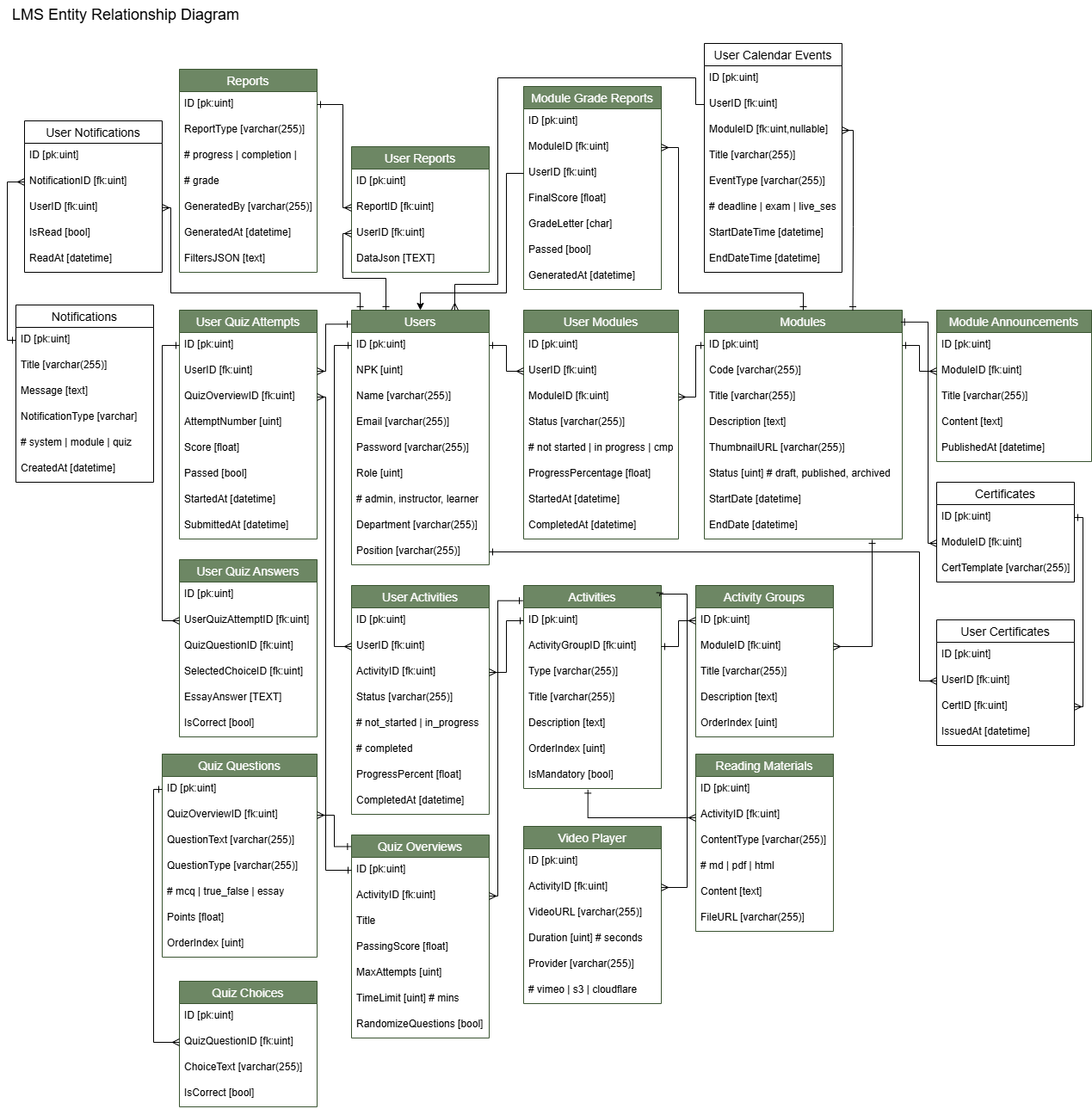
Here’s the DB ERD for the LMS’s personal development:
Architecture: Hexagonal / Clean Architecture
The backend follows hexagonal architecture — also called Ports & Adapters. The goal is simple: the core business logic knows nothing about HTTP, databases, or any infrastructure detail. It only speaks in terms of domain objects and interfaces.
cmd/
main.go ← wires everything together
internal/
adapter/
config/ ← env + config parsing
storage/
postgres/ ← GORM connection wrappers
redis/ ← Redis client wrapper
handler/ ← HTTP handlers (Gin) + middleware
repository/ ← GORM implementations of port interfaces
core/
domain/ ← pure Go structs, enums, DTOs, errors
port/ ← repository + service interfaces
service/ ← business logic (no framework imports)
util/ ← JWT, password hashing, helpers
The layers are enforced by Go's import rules: core/service imports only core/domain and core/port. It never touches adapter/repository or adapter/handler. This means services are trivially testable with mock repositories and the entire business layer compiles without a database.
Why Hexagonal Over MVC?
MVC collapses the "model" into a blob that's simultaneously a database row, a business object, and a serialization target. When requirements change — and they always do — you end up modifying database queries inside handler logic or embedding HTTP concerns in what should be pure business rules.
With hexagonal architecture, the TNA approval chain logic lives entirely in service/tna.go. Adding a new approval step, changing the director-threshold rule, or plugging in a notification broker requires touching exactly one file. The HTTP handler just calls svc.ApproveEntry(...) and serializes the result.
Dual-Database Design
One of the more unusual constraints of this project: CBI runs two separate SQL Server databases — the LMS database (modules, activities, quizzes, enrollments, TNA, competencies) and the HR database (henkaten_assy: master_data_karyawan, divisi, departement, section, sub_section).
The HR database is managed by a separate system and is read-only from the LMS's perspective. This means:
- User authentication happens against LMS users, but employee identity (NPK, jabatan, org hierarchy) is resolved from the HR DB.
- Org lookups (department list, division list, section list) JOIN across HR DB tables.
- The JWT access token embeds
kode_jabatan,departement_id,divisi_id,nama_departement, andnama_divisiso handlers never need an extra round-trip to resolve who the caller is and what they can see.
// JWTClaims carries org context so every handler gets it for free
type JWTClaims struct {
ID uint `json:"id"`
NPK int `json:"npk"`
Role Role `json:"role"`
KodeJabatan int `json:"kode_jabatan"`
DepartementID int `json:"departement_id"`
DivisiID int `json:"divisi_id"`
NamaDepartement string `json:"nama_departement"`
NamaDivisi string `json:"nama_divisi"`
jwt.RegisteredClaims
}The UserRepository holds two *postgres.DB handles — dbLMS and dbUser — and uses the correct one depending on which table it's querying. GORM's Raw() lets us write the enriched karyawan SELECT with LEFT JOINs across lookup tables without sacrificing type safety on the scan target:
const karyawanSelect = `
SELECT mdk.*,
ISNULL(div.divisi, '') AS nama_divisi,
ISNULL(dept.departement, '') AS nama_departement,
ISNULL(sec.section, '') AS nama_section
FROM master_data_karyawan mdk
LEFT JOIN divisi div ON mdk.id_divisi = div.id_divisi
LEFT JOIN departement dept ON mdk.id_departement = dept.id_departement
LEFT JOIN section sec ON mdk.id_section = sec.id_section
`JWT: Access + Refresh Token with HttpOnly Cookies
The auth system uses a dual-token strategy:
- Access token — short-lived (configurable, typically 15 minutes), carries all claims the backend needs to authorize a request.
- Refresh token — long-lived (configurable, typically 7 days), used only to mint new access tokens.
Both are stored as HttpOnly, Secure, SameSite=Strict cookies — not in localStorage. This eliminates the entire class of XSS-based token theft. The frontend (Next.js) never sees the token string; it simply sends cookies with every request.
func GenerateJWTToken(
conf *config.JWT,
user *domain.User,
instructor *domain.Instructor,
karyawan *domain.KaryawanSummary,
tokenType domain.TokenType,
) (string, error) {
// resolves signing key, expiry, and builds JWTClaims
// karyawan fields embedded so downstream handlers skip DB lookups
}The middleware extracts and validates the access token, then injects claims into the Gin context. Every handler downstream calls claimsFromCtx(c) — a one-liner that casts c.Get("user") to *domain.JWTClaims. If the cast fails, the request never reaches business logic.
Token refresh hits GET /refresh: it validates the refresh token from the cookie, mints a new access token, and sets it as a new cookie — all without exposing token strings to JavaScript.
Redis: Caching + Rate Limiting
Redis serves two purposes: response caching for expensive aggregate queries and rate limiting to protect public and semi-public endpoints.
Response Caching
The module catalogue endpoint (GET /modules) is queried by every enrolled employee on login and page load. Rather than hitting SQL Server on every request, the handler checks Redis first:
func (h *ModuleHandler) GetModules(c *gin.Context) {
cached, err := h.redis.Get(ctx, "modules:all")
if err == nil {
c.Data(http.StatusOK, "application/json", []byte(cached))
return
}
modules, err := h.svc.GetModules(ctx)
// ...serialize and set in Redis with TTL
h.redis.Set(ctx, "modules:all", serialized, 5*time.Minute)
c.JSON(http.StatusOK, modules)
}Cache invalidation is explicit: when an instructor creates or updates a module, the handler calls h.redis.Del(ctx, "modules:all"). This avoids stale reads without needing a complex invalidation strategy — the data model is simple enough that key-based invalidation is sufficient.
Sliding Window Rate Limiting
The quiz attempt endpoints are the highest-risk surface for abuse — a student can repeatedly hit POST /quiz-attempts/start to get new attempt IDs. A Redis-backed sliding window limiter is applied as middleware:
func RateLimitMiddleware(rdb *redis.Client, limit int, window time.Duration) gin.HandlerFunc {
return func(c *gin.Context) {
key := fmt.Sprintf("rl:%s:%s", c.ClientIP(), c.FullPath())
count, _ := rdb.Incr(ctx, key).Result()
if count == 1 {
rdb.Expire(ctx, key, window)
}
if count > int64(limit) {
c.JSON(http.StatusTooManyRequests, gin.H{"error": "rate limit exceeded"})
c.Abort()
return
}
c.Next()
}
}The key is scoped per (IP, path) so a single user hammering quiz attempts doesn't affect login or module browsing for other users.
RabbitMQ: Async File Processing
Module thumbnails and quiz images go through an asynchronous upload pipeline via RabbitMQ. The synchronous path would block the HTTP response while uploading to Cloudinary, which is unacceptable at 600 concurrent users.
The pattern:
- Handler receives the multipart file, saves it to local disk, and publishes a job message to a RabbitMQ queue.
- Handler responds immediately with a
202 Acceptedand the temporary local URL. - A worker goroutine consumes from the queue, uploads to Cloudinary, updates the DB record with the CDN URL, and deletes the local file.
type UploadJob struct {
EntityType string `json:"entity_type"` // "module_thumbnail" | "quiz_question" | "quiz_choice"
EntityID uint `json:"entity_id"`
LocalPath string `json:"local_path"`
}
func (w *UploadWorker) Start(ctx context.Context) {
msgs, _ := w.ch.Consume("uploads", "", false, false, false, false, nil)
for msg := range msgs {
var job UploadJob
json.Unmarshal(msg.Body, &job)
cdnURL, err := w.cloudinary.Upload(ctx, job.LocalPath)
if err != nil {
msg.Nack(false, true) // requeue on failure
continue
}
w.repo.UpdateThumbnailURL(ctx, job.EntityID, cdnURL)
os.Remove(job.LocalPath)
msg.Ack(false)
}
}Failed uploads are requeued with Nack(..., requeue=true). A dead-letter queue catches jobs that fail repeatedly so they can be inspected without data loss.
The N+1 Problem: Batch Karyawan Lookups
The GET /users endpoint returns all LMS users enriched with their karyawan data. A naive implementation would:
SELECT * FROM users→ N rows- For each user:
SELECT * FROM master_data_karyawan WHERE npk = ?→ N queries
At 600 users, that's 601 SQL round-trips per request. The fix is a single bulk JOIN:
func (ur *UserRepository) GetUsersWithKaryawan(ctx context.Context) ([]domain.UserResponse, error) {
users, _ := ur.GetUsers(ctx)
// collect NPKs
npks := make([]int, 0, len(users))
for _, u := range users {
if u.NPK != nil {
npks = append(npks, *u.NPK)
}
}
// one query for all karyawan
var rows []karyawanRow
ur.db.Raw(karyawanSelect+"WHERE mdk.npk IN ?", npks).Scan(&rows)
// build lookup map
karyawanMap := make(map[int]*domain.KaryawanSummary, len(rows))
for i := range rows {
r := &rows[i]
karyawanMap[*r.NPK] = rowToSummary(r)
}
// merge
result := make([]domain.UserResponse, 0, len(users))
for _, u := range users {
r := domain.UserResponse{ID: u.ID, NPK: u.NPK, Username: u.Username}
if u.NPK != nil {
r.Karyawan = karyawanMap[*u.NPK]
}
result = append(result, r)
}
return result, nil
}2 SQL queries regardless of user count. The IN clause on npk hits the indexed primary key on master_data_karyawan, so the bulk fetch is as fast as a single-row lookup.
Database Indexing Strategy
SQL Server's query planner needs help on a few critical paths. The indexes added:
user_modules — the enrollment table is queried in three common patterns:
- "What modules is this user enrolled in?" →
(user_id) - "Who is enrolled in this module?" →
(module_id) - "Is this user enrolled in this specific module?" → unique constraint
(user_id, module_id)
CREATE UNIQUE INDEX idx_user_module ON user_modules(user_id, module_id);tna_entries — TNA approval queries filter by tna_id (load all entries for a form) and status + current_step (approval queue):
CREATE INDEX idx_tna_entries_tna_id ON tna_entries(tna_id);
CREATE INDEX idx_tna_entries_step_status ON tna_entries(current_step, status);employee_competencies — the skill gap analysis aggregates over (user_id, gap_status):
CREATE UNIQUE INDEX idx_emp_competency ON employee_competencies(user_id, competency_id);
CREATE INDEX idx_emp_competency_gap ON employee_competencies(user_id, gap_status);quiz_attempts — students' ongoing quiz sessions:
CREATE INDEX idx_quiz_attempts_user_quiz ON quiz_attempts(user_id, quiz_id);TNA Approval Chain: Domain-Driven State Machine
The Training Needs Analysis module is the most complex business logic in the system. Each TNA submission contains N entries (one per employee being registered for training), and each entry has its own independent 5-step approval chain:
kadept → kadiv → hr_admin → hr_kadept → [director if price ≥ Rp 2.5M]
The chain is stored as a JSON column (TNAApprovalChain) in nvarchar(max) — SQL Server has no native array type. The domain layer implements the state machine:
func NextStep(completed ApprovalStep, requiresDirector bool) ApprovalStep {
switch completed {
case StepKadept: return StepKadiv
case StepKadiv: return StepHRAdmin
case StepHRAdmin: return StepHRKadept
case StepHRKadept:
if requiresDirector { return StepDirector }
return "" // chain complete
case StepDirector: return ""
}
return ""
}Authorization is purely kodeJabatan-based — not LMS role. A user with role=instructor and kodeJabatan=0 has no approval permissions, while a user with role=user and kodeJabatan=3 (department head) can approve at the kadept and hr_kadept steps. This is enforced in the service layer before any state transition:
func authoriseStep(step ApprovalStep, kodeJabatan int) error {
switch step {
case StepKadept: if kodeJabatan != 3 { return ErrTNAUnauthorisedStep }
case StepKadiv: if kodeJabatan != 2 { return ErrTNAUnauthorisedStep }
case StepHRAdmin: if kodeJabatan != 4 { return ErrTNAUnauthorisedStep }
case StepHRKadept: if kodeJabatan != 3 { return ErrTNAUnauthorisedStep }
case StepDirector: if kodeJabatan != 1 && kodeJabatan != 2 {
return ErrTNAUnauthorisedStep
}
}
return nil
}After each entry approval, the service recomputes the TNA header's aggregate status from its entries — all approved → fully_approved, any rejected → rejected, otherwise submitted. This is pure domain logic with no side effects visible to the DB layer.
Batch approval (PUT /tna/entries/batch-approve) processes N entries in a loop, collecting per-entry errors, and returns HTTP 207 (Multi-Status) when some succeed and some fail. The frontend can surface exactly which entries failed without losing the successful ones.
Quiz Management Under Load
Quizzes present a specific concurrency concern: when a module goes live and 50 employees open the quiz simultaneously, the naive implementation would create 50 quiz attempts in a race condition.
Three mechanisms work together:
1. Idempotency guard on attempt creation. Before inserting a new quiz_attempt, the service checks for an existing in_progress attempt for (user_id, quiz_id). If one exists, it returns it rather than creating a duplicate.
func (s *QuizService) StartQuizAttempt(ctx context.Context, userID int, quizID uint) (*domain.QuizAttempt, error) {
existing, err := s.repo.GetActiveAttempt(ctx, userID, quizID)
if err == nil && existing != nil {
return existing, nil // idempotent — return the in-progress attempt
}
return s.repo.CreateAttempt(ctx, &domain.QuizAttempt{
UserID: userID,
QuizID: quizID,
Status: domain.AttemptInProgress,
StartedAt: time.Now(),
})
}2. Answer submission is additive, not idempotent-by-default. PUT /quiz-answers/:id updates the existing answer record, not inserts a new one — preventing duplicate answer rows if a student's client retries.
3. Quiz submission is final. PUT /quiz-attempts/:id/submit transitions the attempt to submitted, calculates the score server-side by comparing the student's answers against the correct choices (stored as is_correct on quiz choices), and refuses re-submission if the attempt is already finalized.
Score calculation happens entirely in Go — never on the client — so the result can't be tampered with. The scoring logic walks quiz_answers joined with quiz_choices and counts correct selections against the total question count.
Competency System: Kamus Kompetensi
The competency module implements the company's 2022 Kamus Kompetensi Gol 1-3 — a sparse matrix of 243 competencies × 112 job roles × proficiency levels (2=Basic, 3=Intermediate, 4=Advanced).
The matrix is seeded from a Go slice of SeedRequirement structs (role name × competency seq_no × level). The seeder uses ON CONFLICT DO NOTHING semantics via GORM's FirstOrCreate to be idempotent — safe to run repeatedly in CI.
Skill gap analysis computes, per employee per competency:
gap_status = "met" if actual_level >= required_level
= "gap" if actual_level < required_level
= "exceeds" if actual_level > required_level
= "unrated" if actual_level == 0
The EmployeeGapSummary aggregation runs as a single SQL GROUP BY query rather than iterating in Go:
SELECT
gap_status,
COUNT(*) AS count
FROM employee_competencies
WHERE user_id = ?
GROUP BY gap_statusThen Go maps the result rows into a EmployeeGapSummary struct. This keeps the aggregation in the database where it belongs and avoids loading N competency rows into memory just to count them.
Gin Router Design: Static Before Parametric
Gin uses a radix tree for routing. A common footgun is registering a wildcard route before a static route with the same prefix:
// BAD — gin matches /:id before /me
r.GET("/tna/:id", handler.GetTNAByID)
r.GET("/tna/me", handler.GetMyTNAs) // never reached
// CORRECT — static routes first
r.GET("/tna/me", handler.GetMyTNAs)
r.GET("/tna/entries/:id", handler.GetTNAEntryByID)
r.GET("/tna/entries/batch-approve", handler.BatchApproveEntries) // before /:id
r.GET("/tna/:id", handler.GetTNAByID)This bit me early in development when /modules/me, /modules/enrolled, and /modules/enroll all conflicted with /modules/:id. The fix: register all literal-segment routes before any wildcard on the same prefix.
Role-Based Access: Three Middleware Layers
Access control is enforced at three levels:
1. AuthMiddleware — validates the JWT from the HttpOnly cookie or Authorization: Bearer header. Aborts with 401 if missing or expired.
2. RoleMiddleware — checks claims.Role against an allowlist. Used on instructor-only routes (module CRUD, activity management, report generation) and admin-only routes (hard deletes, user management).
3. Service-layer authorization — for org-hierarchy decisions that can't be expressed as a simple role check. Example: TNA approvals use claims.KodeJabatan inside service.ApproveTNA to enforce which step a user can act on. A department head (kodeJabatan=3) cannot approve the division head step (kadiv) even if they have role=instructor.
This layering means the HTTP layer is "dumb" — it just validates auth tokens. All business rules about who can do what live in the service layer where they're testable without spinning up an HTTP server.
JSON Columns for Structured Data in SQL Server
SQL Server has no native array or JSON column type equivalent to PostgreSQL's jsonb. For fields that need to store ordered lists (TNA approval chains, quiz answer selections, competency course structures), I use nvarchar(max) with a custom GORM scanner:
type TNAApprovalChain []TNAApprovalRecord
func (c TNAApprovalChain) Value() (driver.Value, error) {
if c == nil { return "[]", nil }
b, _ := json.Marshal(c)
return string(b), nil
}
func (c *TNAApprovalChain) Scan(value any) error {
raw, ok := value.(string)
if !ok { return fmt.Errorf("unsupported type %T", value) }
return json.Unmarshal([]byte(raw), c)
}The same pattern is used for StringSlice (prerequisites, contacts, course structure, taglines on modules), TNAImplementationDetailsCol (HR admin's procurement data on TNA entries), and quiz SelectedQuestionIDs. The type implements driver.Valuer and sql.Scanner — GORM reads and writes it transparently without any special handling in handlers or services.
What I'd Do Differently
A few things I'd change with hindsight:
Database: SQL Server on Azure worked well for a company already standardized on Microsoft infrastructure, but the lack of jsonb, partial indexes, and RETURNING makes certain patterns more verbose than PostgreSQL equivalents. Given a greenfield project I'd choose Postgres.
Search: Module and competency search is currently a LIKE %query% full-table scan. At 600 users the performance is acceptable, but adding CONTAINS full-text search on SQL Server, or routing search to Elasticsearch, would be the right call if the module catalogue grows significantly.
Observability: Structured logging with zerolog is in place, but distributed tracing (OpenTelemetry) and a proper metrics pipeline (Prometheus + Grafana) would make diagnosing slow queries and latency spikes much faster in production.
Worker pool: The RabbitMQ consumer is a single goroutine. A bounded worker pool using errgroup would let multiple uploads process in parallel without risking unbounded goroutine growth.
Numbers
| Metric | Value |
|---|---|
| Active users | 600+ |
| Modules in catalogue | 80+ (growing) |
| Competencies in matrix | 243 |
| Job roles in matrix | 112 |
| TNA approval steps | 5 (conditional director gate) |
| Quiz questions (total) | 1,200+ |
| API endpoints | 120+ |
| Avg. response time (cached) | < 10ms |
| Avg. response time (uncached) | 40–120ms |
Closing Thoughts
Building an LMS for a whole company is a different challenge than building one for a SaaS product. There's no gradual rollout — everyone uses it on day one. The users range from production-floor operators checking their module assignments to directors approving multi-million-rupiah training budgets through a 5-step chain. The system has to be correct, not just fast.
Hexagonal architecture paid off more than any other decision. When the TNA approval logic changed from a header-level chain to a per-entry chain (mid-project), the service layer was the only thing that changed. The HTTP handlers, database schema migration, and frontend API contracts updated independently without the usual cascade of changes through a tightly-coupled codebase.
The full source is private (company project), but I'm happy to walk through any of these designs in more depth. The patterns here — dual-database GORM setup, JWT with embedded org claims, Redis sliding-window rate limiting, RabbitMQ async uploads, per-entry approval state machines — are all things I'd carry into any backend engineering role.
Written by Yehezkiel | Go Backend Engineer Technologies: Go · Gin · GORM · SQL Server · Redis · RabbitMQ · Cloudinary · Next.js